美国华盛顿大学的研究团队在语音识别与机器翻译领域取得了一项突破性进展,成功研发出一种名为“空间语音翻译”的创新技术。这项技术能够精准识别并翻译同一空间内多人同时发出的语音,解决了长期以来困扰远程会议、跨国协作和实时通信的“鸡尾酒会效应”难题。
技术原理:声学与算法的深度融合
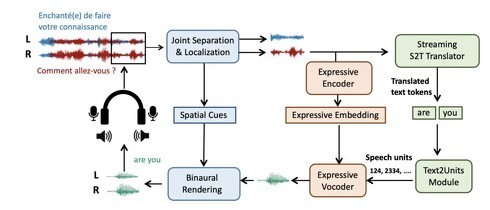
“空间语音翻译”技术的核心,在于将先进的声学空间感知技术与深度神经网络翻译模型进行深度融合。研究团队利用分布式麦克风阵列,配合创新的声源分离算法,首先在物理层面将混杂的语音流依据声源的空间位置进行分离和增强。这类似于人耳利用双耳效应在嘈杂环境中聚焦于特定说话者。
分离出的每一条纯净语音流被送入一个经过海量多语言语料训练的自适应神经网络翻译引擎。该引擎不仅能进行高准确率的语音转文本识别,还能根据上下文和说话者的语言习惯,进行近乎实时的多语言互译。最关键的是,系统通过独特的“说话者ID”跟踪技术,能将翻译后的文本或语音,准确地“投射”回虚拟会议界面对应的原始发言者位置或头像上,实现了“谁在说、说什么、译什么”的清晰对应。
应用前景:重塑网络通信与协作模式
这项技术的潜在应用场景极为广泛,将深刻重塑未来的网络通信模式:
- 跨国远程会议与协作:在拥有多位不同母语参与者的国际视频会议中,系统可以实时提供每位发言者的翻译字幕或同声传译音频,且互不干扰,极大提升沟通效率,打破语言壁垒。
- 沉浸式教育与培训:在全球性的在线课堂或研讨会上,学生和讲师可以自由地用母语提问与回答,系统提供无缝翻译,创造真正无国界的学习环境。
- 国际活动与媒体直播:在新闻发布会、国际赛事或多语种网络直播中,可为不同语言的观众提供个性化的实时解说或字幕服务。
- 智能客服与公共服务:在机场、医院、跨国企业的客服中心,可帮助服务人员同时处理多位不同语言顾客的咨询。
- 社交娱乐与虚拟空间:在元宇宙、多人在线游戏等虚拟社交场景中,实现全球用户无障碍的实时语音交流。
网络技术研发的协同挑战与未来方向
“空间语音翻译”技术的落地与普及,也对底层网络技术研发提出了新的要求与挑战:
- 高带宽与低延迟传输:多路高质量音频流及翻译数据的同时传输,需要更强大的网络带宽保障。而实时交互场景对端到端的延迟极为敏感,这推动了5G-A及6G网络中超低延迟通信技术的研发。
- 边缘计算与云计算协同:为了降低延迟并保护隐私,部分声学处理和初步识别任务可在用户终端或网络边缘完成,而复杂的翻译模型推理则可能依托云端强大的算力。这需要研发更高效的云边端协同计算架构。
- 数据安全与隐私保护:处理多人的实时语音数据涉及严峻的隐私安全问题。未来的研发需集成同态加密、联邦学习等隐私计算技术,确保语音数据在传输和处理过程中得到充分保护。
- 标准化与协议兼容:为了使该技术能广泛应用于各种会议软件、通信平台和硬件设备,需要产业界共同推动相关音频格式、传输协议和接口的标准化工作。
华盛顿大学的这项突破,标志着人机交互和跨语言通信向前迈出了关键一步。它不仅是人工智能在感知智能和认知智能结合上的典范,也作为一项前沿的网络应用,倒逼和牵引着底层网络技术的革新。随着技术的不断成熟和网络基础设施的持续演进,“空间语音翻译”有望像今天的实时字幕一样,成为全球数字生活中一项不可或缺的基础服务,让人类在数字空间中的沟通真正实现“天涯若比邻,言语皆可通”。









